Poslední aktualizace: 15 Jan, 2025

Extrahování textu z PDF souboru pomocí Pythonu
V tomto článku vám ukážeme jak extrahovat text z PDF souboru pomocí Pythonu.
PDF (Portable Document Format) je populární digitální formát dokumentů. Tento formát je navržen tak, aby dokumenty mohly být snadno a spolehlivě zobrazovány nebo sdíleny, bez ohledu na software, hardware či operační systém. Soubory PDF mají příponu .pdf.
Pro extrahování textu z PDF souboru v Pythonu se běžně používají následující knihovny. Ukážeme vám, jak extrahovat text z PDF pomocí obou.
Jak extrahovat text z PDF souboru pomocí pypdf v Pythonu
Zde jsou kroky.
- Nainstalujte pypdf
- Spusťte kód uvedený v tomto článku
- Zobrazte výstup
Instalace pypdf
pypdf můžete nainstalovat pomocí následujícího příkazu
pip install pypdf
Ukázkový kód pro extrahování textu z PDF pomocí pypdf
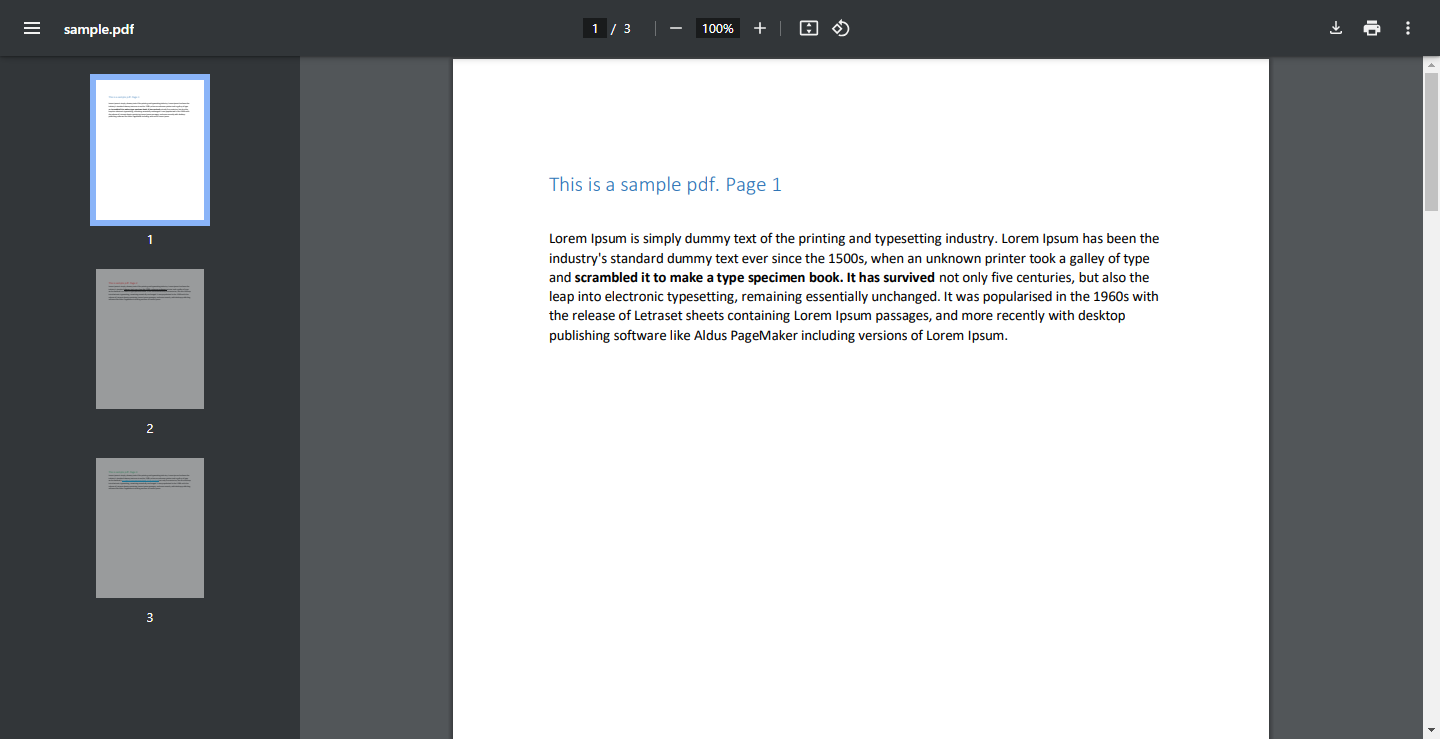
sample.pdf – Stáhnout soubor (Tento ukázkový PDF bude použit v kódu, ale můžete samozřejmě použít svůj vlastní PDF.)
snímek obrazovky sample.pdf
Kód
Zde je kompletní příklad kódu pro extrahování textu z PDF pomocí pypdf.
Výstup
Zde je výstup ukázkového kódu uvedeného výše.
Jak extrahovat text z PDF souboru pomocí PyMuPDF v Pythonu
Zde jsou kroky.
- Nainstalujte PyMuPDF
- Spusťte kód uvedený v tomto článku
- Zobrazte výstup
Instalace PyMuPDF
Nainstalujte PyMuPDF, také známý jako fitz, pomocí následujícího příkazu.
pip install pymupdf
Ukázkový kód pro extrahování textu z PDF pomocí PyMuPDF
Použili jsme stejný PDF soubor jako dříve.
sample.pdf – Stáhnout soubor (Tento ukázkový PDF bude použit v kódu, ale můžete samozřejmě použít svůj vlastní PDF.)
Kód
Zde je kompletní příklad kódu pro extrahování textu z PDF pomocí PyMuPDF.
Výstup
Zde je výstup ukázkového kódu uvedeného výše.
Závěr
V tomto článku poskytujeme ukázkový Python kód, ukázkový soubor a jejich výstup, abychom demonstrovali, jak extrahovat text z PDF pomocí dvou knihoven: PyPDF a PyMuPDF.
Máte-li jakékoli otázky nebo narazíte na problémy při spouštění kódu, neváhejte zanechat komentář v našem fóru!