Zuletzt aktualisiert: 15. Jan, 2025

Text aus PDF-Datei mit Python extrahieren
In diesem Artikel zeigen wir Ihnen, wie Sie Text aus einer PDF-Datei mit Python extrahieren können.
PDF steht für Portable Document Format - ein beliebtes digitales Dokumentenformat. Dieses Format ist so konzipiert, dass Dokumente unabhängig von Software, Hardware oder Betriebssystem einfach und zuverlässig angezeigt oder geteilt werden können. PDF-Dateien haben die Dateiendung .pdf.
Um Text aus einer PDF-Datei mit Python zu extrahieren, werden üblicherweise folgende Bibliotheken verwendet. Wir zeigen Ihnen, wie Sie mit beiden Text aus einer PDF extrahieren können.
Wie man mit pypdf in Python Text aus einer PDF-Datei extrahiert
Hier sind die Schritte.
- pypdf installieren
- Den Code aus diesem Artikel ausführen
- Die Ausgabe ansehen
pypdf installieren
Sie können pypdf mit folgendem Befehl installieren
pip install pypdf
Beispielcode zur Textextraktion aus PDF mit pypdf
sample.pdf - Download-Link (Diese Beispiel-PDF wird im Code verwendet, aber Sie können natürlich auch Ihre eigene PDF verwenden.)
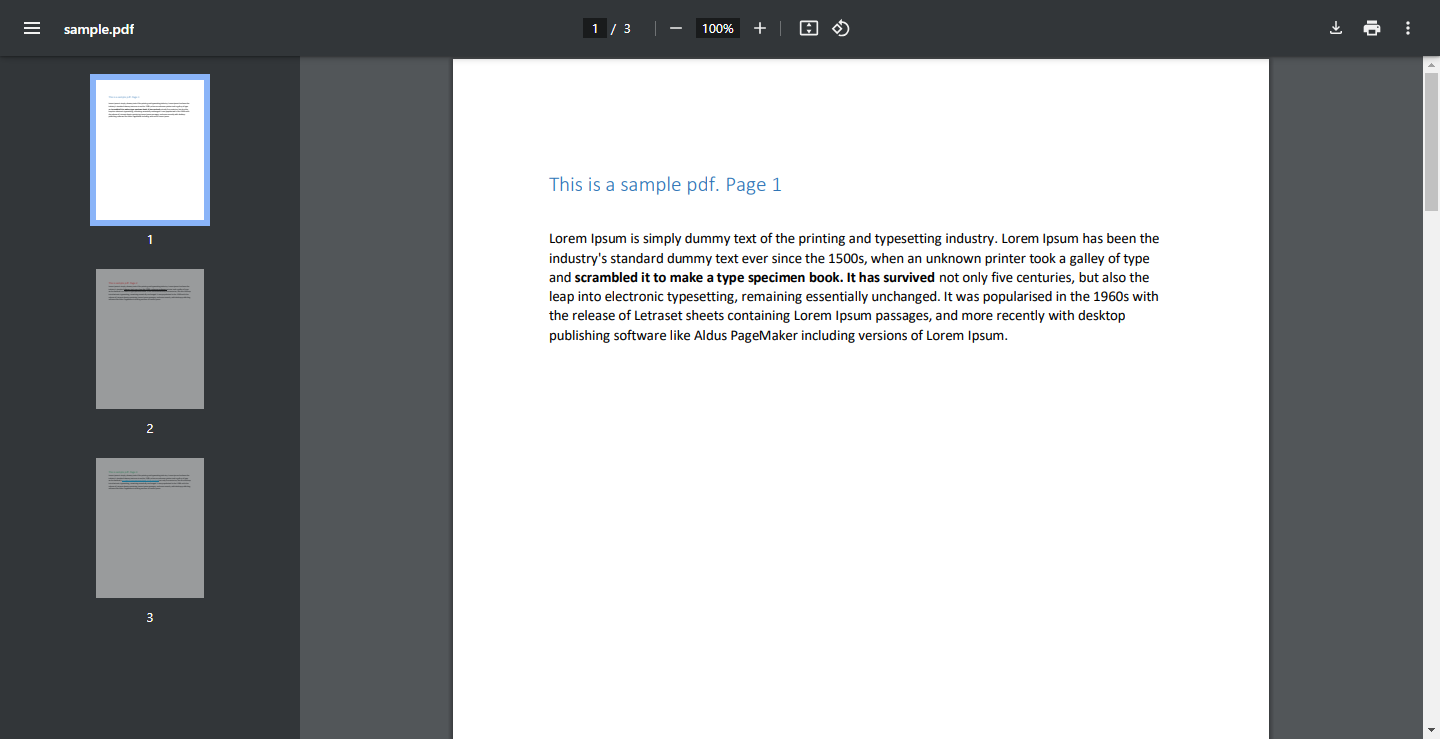
Screenshot von sample.pdf
Code
Hier ist ein vollständiges Codebeispiel für die Extraktion von Text aus einer PDF mit pypdf.
Ausgabe
Hier ist die Ausgabe des oben bereitgestellten Beispielcodes.
Wie man mit PyMuPDF in Python Text aus einer PDF-Datei extrahiert
Hier sind die Schritte.
- PyMuPDF installieren
- Den Code aus diesem Artikel ausführen
- Die Ausgabe ansehen
Installieren Sie PyMuPDF
Installieren Sie PyMuPDF, auch bekannt als fitz, mit folgendem Befehl.
pip install pymupdf
Beispielcode zur Textextraktion aus PDF mit PyMuPDF
Wir verwendeten dieselbe PDF wie zuvor
sample.pdf - Download-Link (Diese Beispiel-PDF wird im Code verwendet, aber Sie können natürlich auch Ihre eigene PDF verwenden.)
Code
Hier ist ein vollständiges Codebeispiel für die Extraktion von Text aus einer PDF mit PyMuPDF.
Ausgabe
Hier ist die Ausgabe des oben bereitgestellten Beispielcodes.
Fazit
In diesem Artikel stellen wir einen Beispielcode in Python, eine Beispieldatei und deren Ausgabe bereit, um zu demonstrieren, wie man Text aus einer PDF mithilfe von zwei Bibliotheken: PyPDF und PyMuPDF extrahiert.
Wenn Sie Fragen haben oder auf Probleme beim Ausführen des Codes stoßen, hinterlassen Sie gerne einen Kommentar in unseren Foren!