Última actualización: 15 Ene, 2025

Extraer texto de un archivo PDF usando Python
En este artículo, te informaremos cómo extraer texto de un archivo PDF usando Python.
PDF significa Formato de Documento Portátil, es un formato de documento digital popular. Este formato está diseñado para permitir que los documentos se vean o compartan fácil y confiablemente, independientemente del software, hardware o sistema operativo. Los archivos PDF tienen la extensión .pdf.
Para extraer texto de un archivo PDF usando Python, estas bibliotecas son comúnmente utilizadas. Te mostraremos cómo extraer texto de un PDF usando ambas.
Cómo extraer texto de un archivo PDF usando pypdf en Python
Aquí están los pasos.
- Instalar pypdf
- Ejecutar el código dado en este artículo
- Ver el resultado
Instalar pypdf
Puedes instalar pypdf usando el siguiente comando
pip install pypdf
Código de muestra para extraer texto de PDF usando pypdf
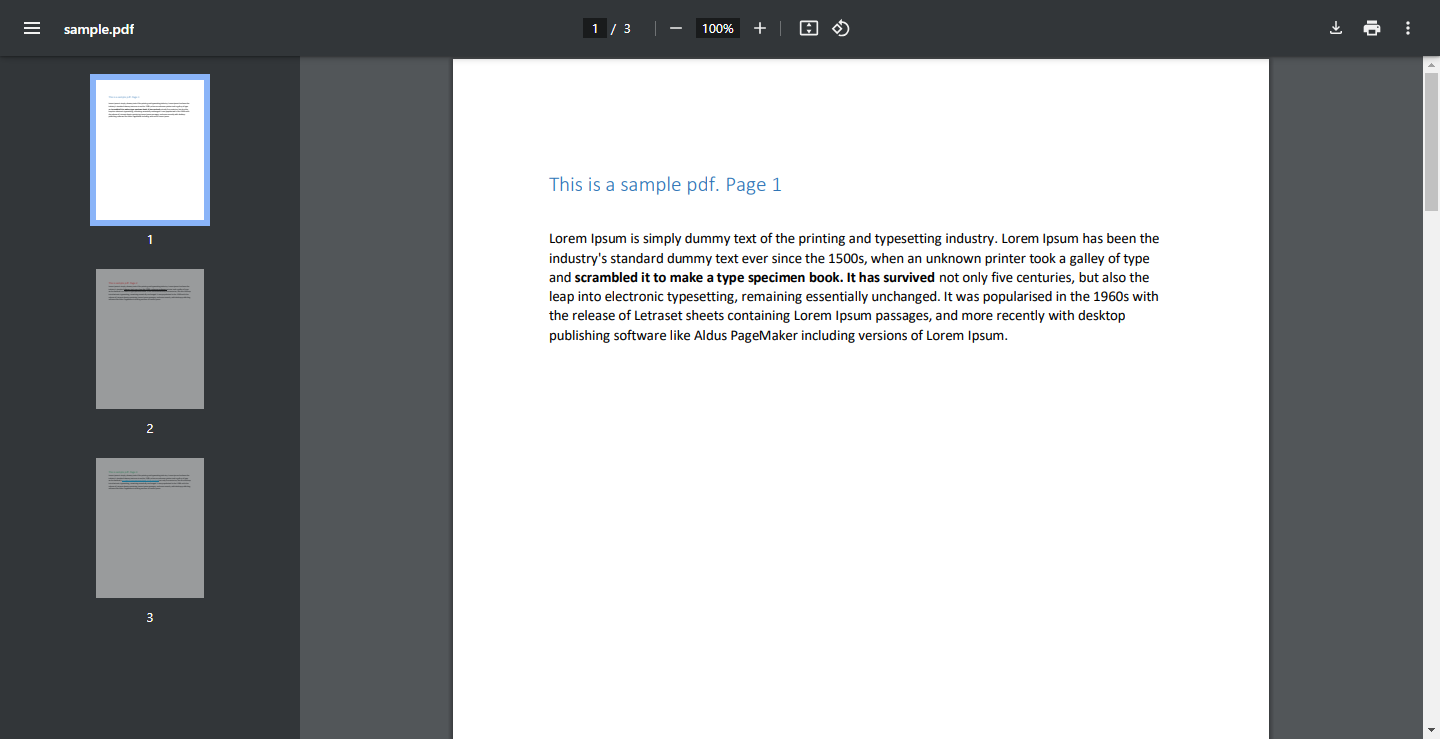
sample.pdf - Enlace de descarga (Este PDF de muestra se usará en el código, pero ciertamente puedes usar tu propio PDF).
captura de pantalla de sample.pdf
Código
Aquí hay un ejemplo de código completo para extraer texto de un PDF usando pypdf.
Resultado
Aquí está el resultado del código de muestra proporcionado anteriormente.
Cómo extraer texto de un archivo PDF usando PyMuPDF en Python
Aquí están los pasos.
- Instalar PyMuPDF
- Ejecutar el código dado en este artículo
- Ver el resultado
Instalar PyMuPDF
Instala PyMuPDF, también conocido como fitz, usando el siguiente comando.
pip install pymupdf
Código de muestra para extraer texto de PDF usando PyMuPDF
Usamos el mismo PDF que antes
sample.pdf - Enlace de descarga (Este PDF de muestra se usará en el código, pero ciertamente puedes usar tu propio PDF).
Código
Aquí hay un ejemplo de código completo para extraer texto de un PDF usando PyMuPDF.
Resultado
Aquí está el resultado del código de muestra proporcionado anteriormente.
Conclusión
En este artículo, proporcionamos un código de muestra en Python, un archivo de muestra y sus resultados para demostrar cómo extraer texto de un PDF utilizando dos bibliotecas: PyPDF y PyMuPDF.
Si tienes alguna pregunta o encuentras algún problema al ejecutar el código, ¡no dudes en dejar un comentario en nuestros foros!