Dernière mise à jour: 15 Janvier, 2025

Extraire du texte d’un fichier PDF à l’aide de Python
Dans cet article, nous allons vous montrer comment extraire du texte d’un fichier PDF à l’aide de Python.
PDF, qui signifie Portable Document Format, est un format de document numérique populaire. Ce format est conçu pour permettre aux documents d’être visualisés ou partagés facilement et de manière fiable, quel que soit le logiciel, le matériel ou le système d’exploitation. Les fichiers PDF ont l’extension .pdf.
Pour extraire du texte d’un fichier PDF à l’aide de Python, ces bibliothèques sont couramment utilisées. Nous vous montrerons comment extraire du texte d’un PDF en utilisant les deux.
Comment extraire du texte d’un fichier PDF à l’aide de pypdf en Python
Voici les étapes.
- Installer pypdf
- Exécuter le code donné dans cet article
- Voir le résultat
Installer pypdf
Vous pouvez installer pypdf en utilisant la commande suivante
pip install pypdf
Code d’exemple pour extraire du texte d’un PDF en utilisant pypdf
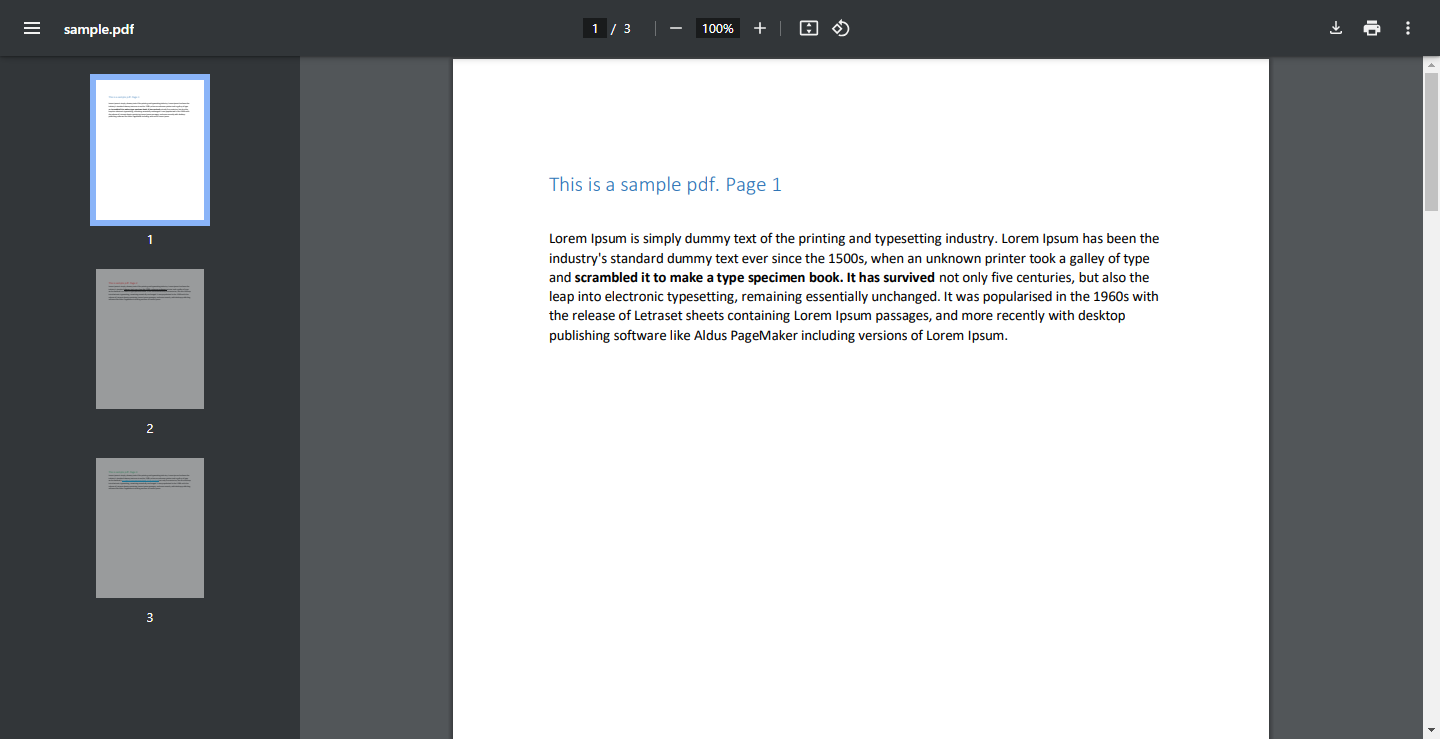
sample.pdf - Lien de téléchargement (Ce PDF d’exemple sera utilisé dans le code, mais vous pouvez certainement utiliser votre propre PDF.)
capture d’écran de sample.pdf
Code
Voici un exemple de code complet pour extraire du texte d’un PDF en utilisant pypdf.
Résultat
Voici le résultat du code d’exemple fourni ci-dessus.
Comment extraire du texte d’un fichier PDF à l’aide de PyMuPDF en Python
Voici les étapes.
- Installer PyMuPDF
- Exécuter le code donné dans cet article
- Voir le résultat
Installer PyMuPDF
Installez PyMuPDF, aussi connu sous le nom de fitz, en utilisant la commande suivante.
pip install pymupdf
Code d’exemple pour extraire du texte d’un PDF en utilisant PyMuPDF
Nous avons utilisé le même PDF qu’avant
sample.pdf - Lien de téléchargement (Ce PDF d’exemple sera utilisé dans le code, mais vous pouvez certainement utiliser votre propre PDF.)
Code
Voici un exemple de code complet pour extraire du texte d’un PDF en utilisant PyMuPDF.
Résultat
Voici le résultat du code d’exemple fourni ci-dessus.
Conclusion
Dans cet article, nous proposons un code Python d’exemple, un fichier d’exemple et leur résultat pour démontrer comment extraire du texte d’un PDF en utilisant deux bibliothèques: PyPDF et PyMuPDF.
Si vous avez des questions ou rencontrez des problèmes lors de l’exécution du code, n’hésitez pas à laisser un commentaire dans nos forums !