마지막 업데이트: 2025년 1월 15일

Python을 사용하여 PDF 파일에서 텍스트 추출하기
이 글에서는 Python을 사용하여 PDF 파일에서 텍스트를 추출하는 방법을 알려드립니다.
PDF는 Portable Document Format의 약자로, 소프트웨어, 하드웨어 또는 운영체제에 상관없이 문서를 쉽게 보고 공유할 수 있도록 설계된 디지털 문서 형식입니다. PDF 파일의 확장자는 .pdf입니다.
Python을 사용하여 PDF 파일에서 텍스트를 추출하려면 이와 같은 라이브러리를 주로 사용합니다. 두 가지 라이브러리를 사용하여 PDF에서 텍스트를 추출하는 방법을 보여드리겠습니다.
Python에서 pypdf를 사용하여 PDF 파일에서 텍스트 추출하는 방법
단계는 다음과 같습니다.
- pypdf 설치
- 이 글에서 제공한 코드 실행
- 출력 확인
pypdf 설치
다음 명령어를 사용하여 pypdf를 설치할 수 있습니다.
pip install pypdf
pypdf를 사용하여 PDF에서 텍스트를 추출하는 샘플 코드
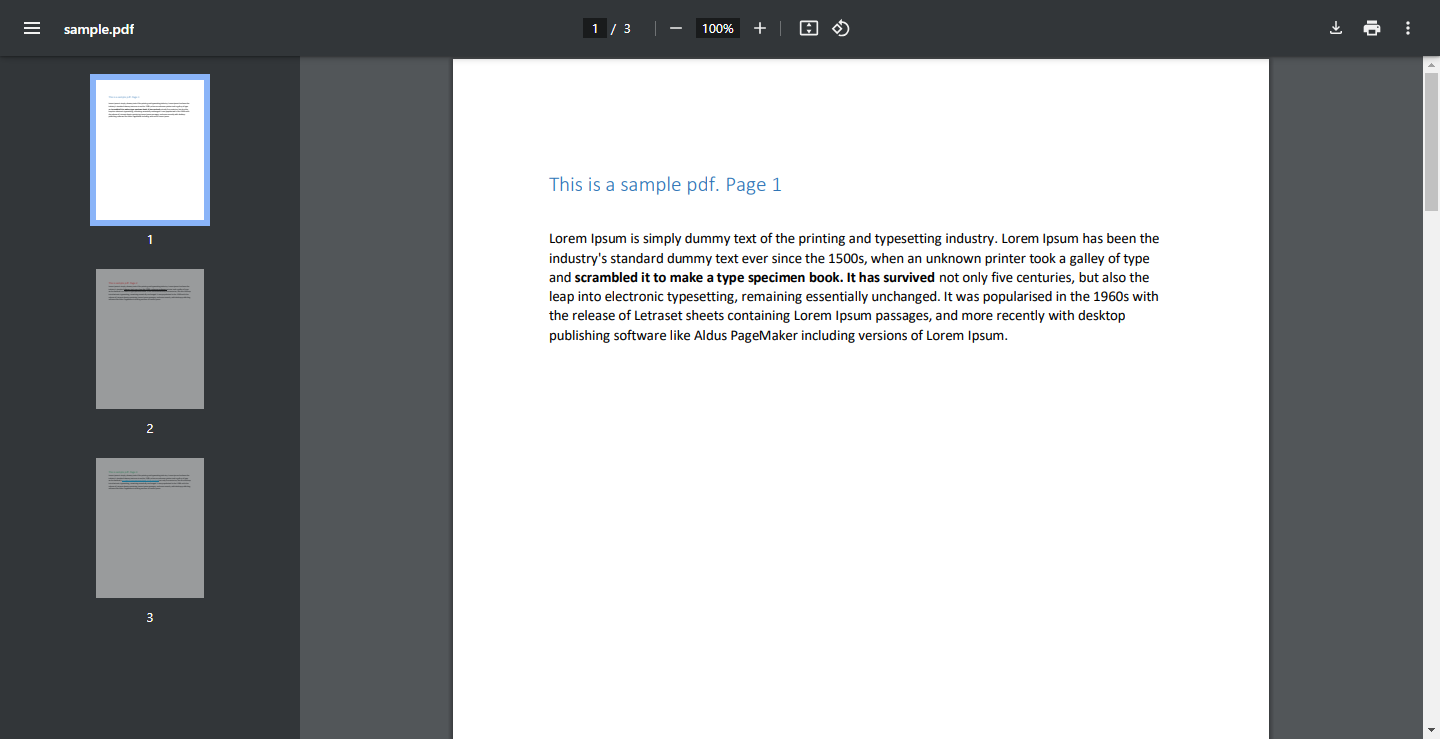
sample.pdf - 다운로드 링크 (이 샘플 PDF는 코드에서 사용됩니다. 하지만 본인의 PDF를 사용할 수도 있습니다.)
샘플 PDF 스크린샷
코드
여기 pypdf를 사용하여 PDF에서 텍스트를 추출하는 완전한 코드 예제가 있습니다.
출력
위에서 제공한 샘플 코드의 출력은 다음과 같습니다.
Python에서 PyMuPDF를 사용하여 PDF 파일에서 텍스트 추출하는 방법
단계는 다음과 같습니다.
- PyMuPDF 설치
- 이 글에서 제공한 코드 실행
- 출력 확인
PyMuPDF 설치
PyMuPDF 또는 fitz라고도 불리는 프로그램을 설치하려면 다음 명령어를 사용하세요.
pip install pymupdf
PyMuPDF를 사용하여 PDF에서 텍스트를 추출하는 샘플 코드
이전에 사용한 동일한 PDF를 사용합니다.
sample.pdf - 다운로드 링크 (이 샘플 PDF는 코드에서 사용됩니다. 하지만 본인의 PDF를 사용할 수도 있습니다.)
코드
여기 PyMuPDF를 사용하여 PDF에서 텍스트를 추출하는 완전한 코드 예제가 있습니다.
출력
위에서 제공한 샘플 코드의 출력은 다음과 같습니다.
결론
이 글에서는 PyPDF 및 PyMuPDF라는 두 가지 라이브러리를 사용하여 PDF에서 텍스트를 추출하는 방법을 설명하기 위해 샘플 Python 코드, 샘플 파일 및 그 출력을 제공합니다.
코드를 실행하는 동안 질문이나 문제가 발생하면 우리 포럼에 댓글로 남겨 주세요!