Ostatnia aktualizacja: 29 stycznia, 2025

W tym artykule przedstawimy, jak pracować z plikami PDF używając Pythona. W tym celu wykorzystamy bibliotekę pypdf.
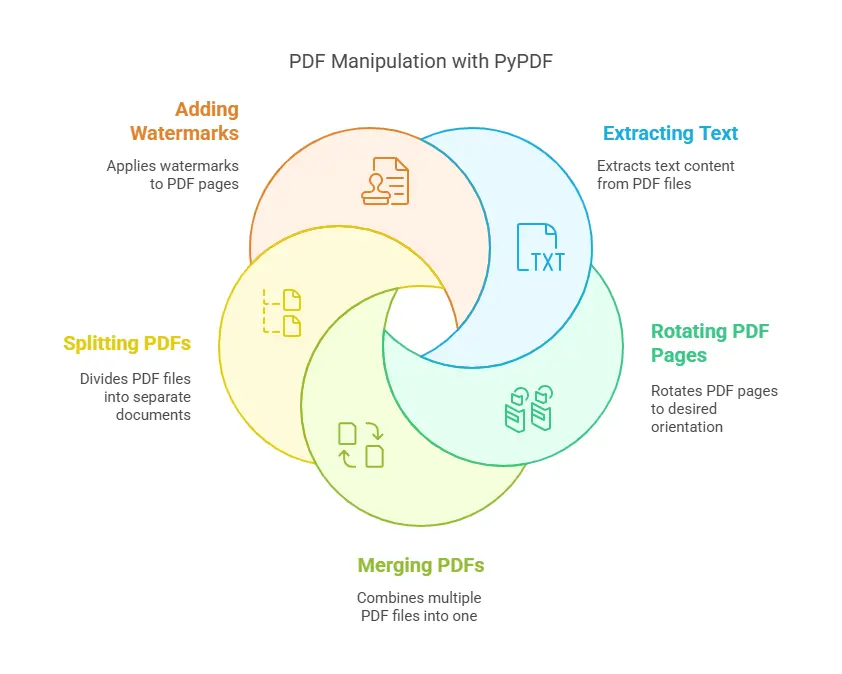
Używając biblioteki pypdf, pokażemy, jak wykonać następujące operacje w Pythonie:
- Wyciąganie tekstu z PDF-ów
- Obracanie stron PDF
- Scalanie wielu PDF-ów
- Dzielenie PDF-ów na osobne pliki
- Dodawanie znaków wodnych do stron PDF
Uwaga: Artykuł zawiera wiele cennych informacji, więc możesz pominąć sekcje, które cię nie interesują! Treść jest uporządkowana dla łatwej nawigacji, więc możesz szybko skupić się na tym, co jest dla ciebie najbardziej istotne.
Przykładowe kody
Możesz pobrać wszystkie przykładowe kody użyte w tym artykule z poniższego linku. Zawiera on kody, pliki wejściowe oraz pliki wyjściowe.
Instalacja pypdf
Aby zainstalować pypdf, wystarczy uruchomić następujące polecenie w terminalu lub wierszu poleceń:
pip install pypdf
Uwaga: Powyższe polecenie jest uwzględniające wielkość liter.
1. Wyciąganie tekstu z pliku PDF przy użyciu Pythona
Wyjaśnienie kodu
1. Tworzenie obiektu czytnika PDF
reader = PdfReader(pdf_file)
PdfReader(pdf_file)ładuje plik PDF do obiektu czytnika.- Ten obiekt umożliwia dostęp do stron i ich zawartości.
2. Iteracja przez strony
for page_number, page in enumerate(reader.pages, start=1):
reader.pageszwraca listę stron w PDF-ie.enumerate(..., start=1)przypisuje numer strony zaczynając od 1.
3. Drukowanie wyekstrahowanego tekstu
print(f"Strona {page_number}:")
print(page.extract_text())
print("-" * 50) # Separator dla lepszej czytelności
page.extract_text()wyciąga treść tekstową z bieżącej strony.- Skrypt drukuje wyekstrahowany tekst wraz z numerem strony.
"-" * 50drukuje linię separatora (--------------------------------------------------) dla lepszej czytelności.
Plik PDF użyty w kodzie
- Plik wejściowy: Link do pobrania
Wynik działania kodu
2. Obracanie stron PDF przy użyciu Pythona
Wyjaśnienie kodu
Kod w zasadzie obraca pierwszą stronę o 90° zgodnie z ruchem wskazówek zegara i zapisuje zmodyfikowany PDF bez wpływu na pozostałe strony.
1. Importowanie wymaganych klas
from pypdf import PdfReader, PdfWriter
PdfReader: Odczytuje wejściowy PDF.PdfWriter: Tworzy nowy PDF z modyfikacjami.
2. Definiowanie ścieżek plików wejściowych i wyjściowych
input_pdf = "pdf-to-rotate/input.pdf"
output_pdf = "pdf-to-rotate/rotated_output.pdf"
- Skrypt odczytuje plik
input.pdfi zapisuje zmodyfikowany plik jakorotated_output.pdf.
3. Odczyt PDF-a i tworzenie obiektu zapisującego
reader = PdfReader(input_pdf)
writer = PdfWriter()
readerładuje istniejący PDF.writerjest używany do przechowywania zmodyfikowanych stron.
4. Obrót pierwszej strony o 90 stopni
page = reader.pages[0]
page.rotate(90) # Obrót o 90 stopni zgodnie z ruchem wskazówek zegara
writer.add_page(page)
- Wyciąga stronę 1, obraca ją o 90 stopni i dodaje ją do nowego PDF-a.
5. Dodanie pozostałych stron bez zmian
for i in range(1, len(reader.pages)):
writer.add_page(reader.pages[i])
- Przechodzi przez pozostałe strony i dodaje je bez zmian.
6. Zapisanie nowego PDF-a
with open(output_pdf, "wb") as file:
writer.write(file)
- Otwiera
rotated_output.pdfw trybie zapisu binarnego i zapisuje nowy PDF.
7. Wydrukowanie potwierdzenia
print(f"Obrócona strona zapisana w {output_pdf}")
- Wyświetla komunikat o sukcesie.
Wejściowy PDF użyty w kodzie i jego obrócony wynik
- Plik wejściowy PDF: Link do pobrania
- Plik wyjściowy obróconego PDF: Link do pobrania
Zrzut ekranu

3. Scalanie plików PDF przy użyciu Pythona
Ten skrypt w Pythonie pokazuje, jak scalać wiele plików PDF z katalogu w jeden PDF używając biblioteki PyPDF.
Wyjaśnienie kodu
- Skrypt automatycznie scala wszystkie pliki PDF znalezione w określonym katalogu (
pdfs-to-merge) w jeden plik wyjściowy (merged_output.pdf). - Zapewnia istnienie katalogu wyjściowego i dodaje strony każdego PDF-a w porządku, w jakim są wymienione.
- Wynikowy plik zostanie zapisany w podkatalogu
output-dir.
Rozbicie kodu
1. Importowanie bibliotek
import os
from pypdf import PdfReader, PdfWriter
os: Używane do interakcji z systemem plików, takie jak czytanie katalogów i zarządzanie ścieżkami.PdfReader: Odczytuje zawartość pliku PDF.PdfWriter: Tworzy i zapisuje nowy plik PDF.
2. Definiowanie katalogu i pliku wyjściowego
directory = "pdfs-to-merge"
output_file = "output-dir/merged_output.pdf"
directory: Określa folder, w którym przechowywane są pliki PDF.output_file: Definiuje ścieżkę wyjściową i nazwę scalonego PDF-a.
3. Tworzenie katalogu wyjściowego, jeśli nie istnieje
os.makedirs(os.path.join(directory, "output-dir"), exist_ok=True)
- To zapewnia istnienie katalogu wyjściowego, a jeśli nie istnieje, tworzy go.
4. Tworzenie obiektu PdfWriter
writer = PdfWriter()
writerjest używany do zbierania i łączenia wszystkich stron z PDF-ów.
5. Iteracja przez wszystkie pliki PDF w katalogu
for file_name in sorted(os.listdir(directory)):
if file_name.endswith(".pdf"):
file_path = os.path.join(directory, file_name)
print(f"Adding: {file_name}")
- Ta pętla przechodzi przez wszystkie pliki w określonym katalogu, sprawdzając pliki z rozszerzeniem
.pdf. Używasorted(), aby przetwarzać je w porządku alfabetycznym.
6. Odczytanie każdego PDF-a i dodanie stron do zapisującego
reader = PdfReader(file_path)
writer.append(reader)
- Dla każdego PDF-a
PdfReaderodczytuje plik, następnie wszystkie jego strony są dodawane dowriter.
7. Zapisanie scalonego pliku PDF do pliku wyjściowego
output_path = os.path.join(directory, output_file)
with open(output_path, "wb") as output_pdf:
writer.write(output_pdf)
- Po zebraniu wszystkich stron
writer.write()zapisuje scalony PDF do określonej ścieżki wyjściowej.
8. Wydrukowanie potwierdzenia
print(f"Merged PDF saved as: {output_path}")
- Wyświetla komunikat o sukcesie potwierdzający lokalizację zapisanego scalonego PDF-a.
Pliki PDF użyte w kodzie wejściowym i scalony plik wyjściowy
- Wejściowe pliki PDF: Link do pobrania
- Scalony plik wyjściowy PDF: Link do pobrania
4. Dzielenie PDF-a przy użyciu Pythona
Wyjaśnienie kodu
Powyższy skrypt w Pythonie dzieli PDF na oddzielne strony używając biblioteki PyPDF. Najpierw zapewnia, że cena katalogu wyjściowego istnieje, a następnie odczytuje plik PDF wejściowy. Skrypt przechodzi przez każdą stronę, tworzy nowy obiekt PdfWriter i zapisuje każdą stronę jako pojedynczy plik PDF. Pliki wynikowe są nazwane sekwencyjnie (np. page_1.pdf, page_2.pdf) i przechowywane w folderze output-dir. Na końcu drukuje komunikat potwierdzający utworzenie każdego pliku i informuje o zakończeniu procesu.
Wejściowy PDF i podzielone pliki wyjściowe
- Wejściowy plik PDF: Link do pobrania
- Podzielone pliki wyjściowe: Link do pobrania
5. Dodawanie znaku wodnego do PDF-a przy użyciu Pythona
Możesz dodać znak wodny do PDF-a używając biblioteki PyPDF, nakładając PDF ze znakiem wodnym na istniejący PDF. Upewnij się, że PDF ze znakiem wodnym ma tylko jedną stronę, aby prawidłowo zastosować go do każdej strony głównego PDF-a.
Wyjaśnienie kodu
Powyższy skrypt w Pythonie odczytuje wejściowy PDF, wyciąga jednokartkowy PDF znaku wodnego, nakłada znak wodny na każdą stronę wejściowego PDF-a i zapisuje końcowy PDF ze znakiem wodnym.
Rozbicie kodu
Poniżej znajduje się krótkie wyjaśnienie każdej części
1. Importowanie wymaganych klas
from pypdf import PdfReader, PdfWriter
PdfReadersłuży do odczytu istniejących PDF-ów.PdfWritersłuży do tworzenia i zapisu nowego PDF-a.
2. Definiowanie ścieżek plików
input_pdf = "pdf-to-watermark/input.pdf"
watermark_pdf = "pdf-to-watermark/watermark.pdf"
output_pdf = "pdf-to-watermark/output_with_watermark.pdf"
input_pdf: Oryginalny PDF, do którego zostanie dodany znak wodny.watermark_pdf: Osobny jednostronny PDF pełniący rolę znaku wodnego.output_pdf: Plik wyjściowy, który będzie zawierał strony ze znakami wodnymi.
3. Odczyt PDF-ów
reader = PdfReader(input_pdf)
watermark = PdfReader(watermark_pdf)
reader: Odczytuje PDF wejściowy.watermark: Odczytuje PDF ze znakiem wodnym.
4. Tworzenie obiektu zapisującego
writer = PdfWriter()
- Posłuży do stworzenia końcowego PDF-a ze znakiem wodnym.
5. Wyciąganie strony znaku wodnego
watermark_page = watermark.pages[0]
- Zakłada się, że PDF ze znakiem wodnym ma tylko jedną stronę, która będzie użyta do nałożenia na wszystkie strony.
6. Iteracja przez strony wejściowego PDF-a i łączenie znaku wodnego
for page in reader.pages:
# Łączenie znaku wodnego z bieżącą stroną
page.merge_page(watermark_page)
# Dodanie zmodyfikowanej strony do zapisującego
writer.add_page(page)
- Iteruje przez każdą stronę
input_pdf. merge_page(watermark_page)nakłada znak wodny na bieżącą stronę.- Dodaje zmodyfikowaną stronę do
writer.
7. Zapisanie PDF-a ze znakiem wodnym
with open(output_pdf, "wb") as output_file:
writer.write(output_file)
- Zapisuje zmodyfikowane strony do nowego pliku PDF.
8. Wydrukowanie potwierdzenia
print(f"PDF ze znakiem wodnym zapisany jako: {output_pdf}")
- Wyświetla informację o ścieżce do pliku wyjściowego jako potwierdzenie.
Wejściowy PDF, PDF ze znakiem wodnym i wynikowy PDF
- Wejściowy plik PDF: Link do pobrania
- Plik PDF ze znakiem wodnym: Link do pobrania
- Plik wyjściowy PDF ze znakiem wodnym: Link do pobrania
Zrzut ekranu

Podsumowanie
W tym przewodniku przeszliśmy przez podstawowe operacje na plikach PDF w Pythonie, w tym wyciąganie tekstu, obracanie stron, scalanie, dzielenie oraz dodawanie znaków wodnych. Dzięki tym umiejętnościom możesz teraz stworzyć własnego menedżera PDF i automatyzować różne zadania związane z PDF-ami w efektywny sposób.