Last Updated: 15 Jan, 2025

Extract Text from PDF File Using Python
In this article, we will let you know how to extract text from PDF file using Python.
PDF stands for Portable Document Format is a popular digital document format. This format is designed to allow documents to be viewed or shared easily and reliably, regardless of software, hardware or operating system. PDF files have the extension .pdf.
To extract text from a PDF file using Python, these libraries are commonly used. We will show you how to extract text from a PDF using both of them.
How to Extract Text from a PDF File Using pypdf in Python
Here are the steps.
- Install pypdf
- Run the code given in this article
- See the output
Install pypdf
You can install pypdf using the following command
pip install pypdf
Sample Code to Extract Text from PDF using pypdf
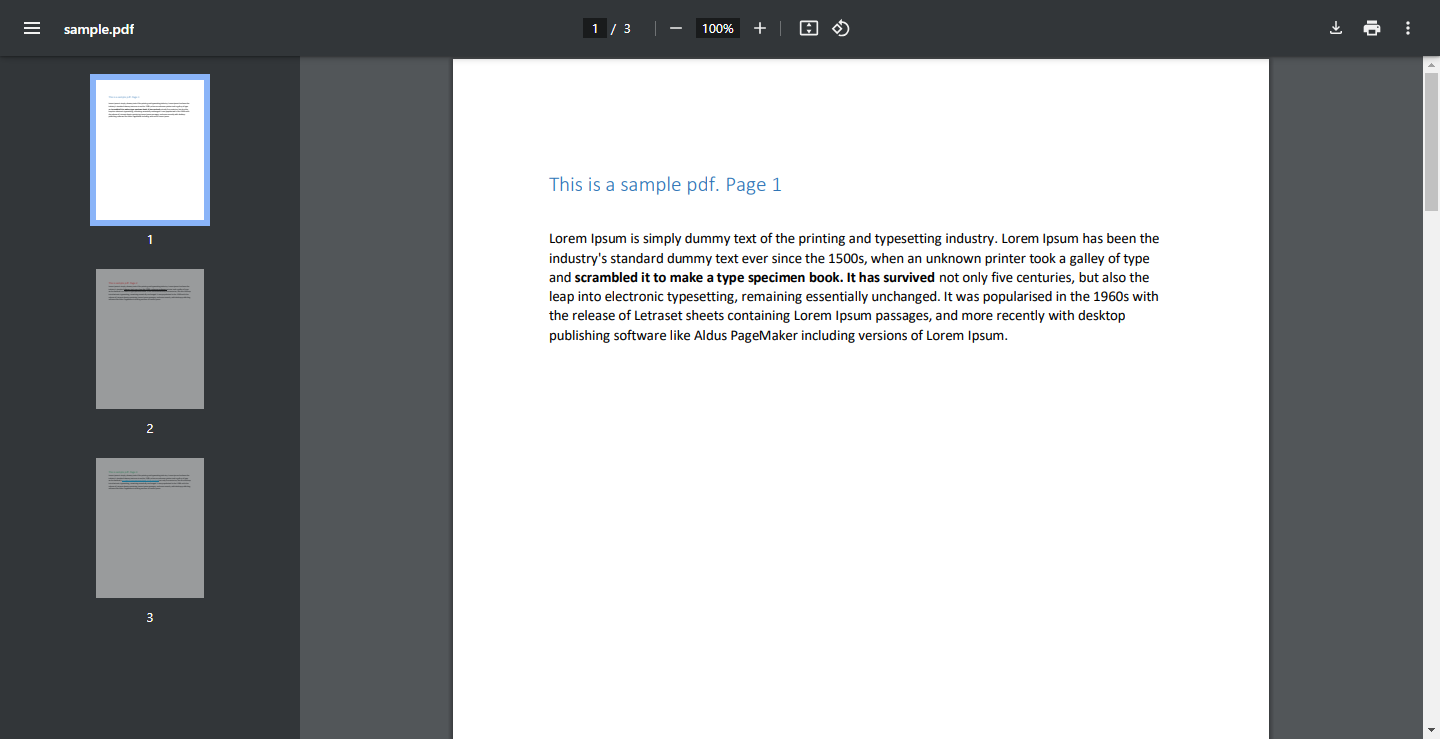
sample.pdf - Download Link (This sample PDF will be used in the code, but you can certainly use your own PDF.)
screenshot of sample.pdf
Code
Here is a complete code example for extracting text from a PDF using pypdf.
Output
Here is the output of the sample code provided above.
How to Extract Text from a PDF File Using PyMuPDF in Python
Here are the steps.
- Install PyMuPDF
- Run the code given in this article
- See the output
Install PyMuPDF
Install PyMuPDF, also known as fitz, using the following command.
pip install pymupdf
Sample Code to Extract Text from PDF using PyMuPDF
We used the same pdf as used before
sample.pdf - Download Link (This sample PDF will be used in the code, but you can certainly use your own PDF.)
Code
Here is a complete code example for extracting text from a PDF using PyMuPDF.
Output
Here is the output of the sample code provided above.
Conclusion
In this article, we provide a sample Python code, a sample file, and their output to demonstrate how to extract text from a PDF using two libraries: PyPDF and PyMuPDF.
If you have any questions or encounter any issues while running the code, feel free to leave a comment in our forums!